The Fediverse has WHAT?
Well, yes. It’s a bit of an overexaggeration in a lot of cases. But there is a genuine vector for abuse there.
If you’re active on the fediverse, you probably have already heard about It’s FOSS complaining and urging users to not share their articles on the Fediverse.
That’s a rather peculiar choice, isn’t it? As a content creator you’d be happy to get your stuff shared, no?
Well, as it turns out, the Fediverse is creating a problem for them. The root of all evil are Link Embeds.
But how?
Let’s demonstrate it with, ironically, the post that “It’s FOSS” published, linking to an article of theirs asking to not share their articles on Mastodon (which they then shared on Mastodon).

You see that pretty image, the headline, and the little example text? Those are the evil things that caused all these issues.
See, when a link gets shared on the Fediverse, it fetches something known as oEmbed metadata (among other things).
To fetch that data, a service has to download the whole webpage (or, well, at
least the <head> section), and parse it. That’s work for both sides. The
fetching side has to download and parse the page, and the serving side has to..
well, serve it.
Usually that works quite well. Someone shares an article on, let’s say, Tumblr. Tumblr fetches the page, parses the metadata, and stores it in the database.
When someone else shares the same link, Tumblr simply reuses the metadata. Saves resources on both sides. Tumblr doesn’t need to re-fetch the preview, and the site the article is hosted on doesn’t need to serve the page again.
But we aren’t Tumblr, are we? We are cool, we are different! We are decentralized, with thousands of servers!
..and that’s where the problem comes in.
Decentralization is cool.. until it isn’t.
Like mentioned above, the Fediverse isn’t a single service with a single database. Rather, it’s a bunch of servers and a bunch of databases loosely connected with each other.
That’s great for users because they can host their own server and integrate neatly into the great whole.
It also comes with a lot of unique problems and challenges, but today we are focussing on one in particular because it’s a hot topic right now and I like to get attention.
So, we went over how these embeds are generated, great. But now imagine this:
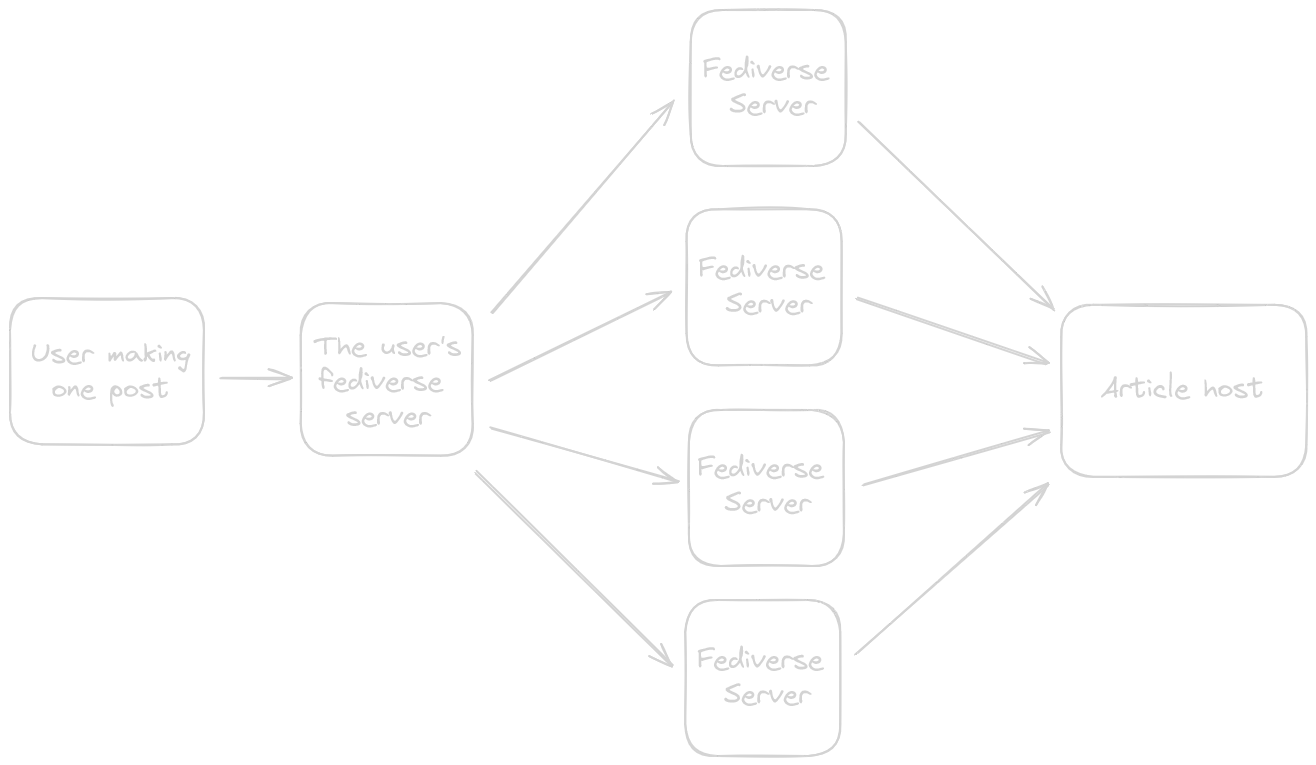
You share a post on the Fediverse and your post goes semi-viral. It gets spread across, let’s say, 10k servers.
That will then result in 10k fetches by the servers to generate the embeds on top of the organic traffic you receive from users trying to load your posts.
That’s basically a DNS amplification attack.. but with Fediverse servers.. a Fedi amplification attack.
To visualize it a bit. This is what happens with the “fedi amplification attack”:
..and this is the visual of a classic DNS amplification attack (as visualized by Cloudflare themselves):
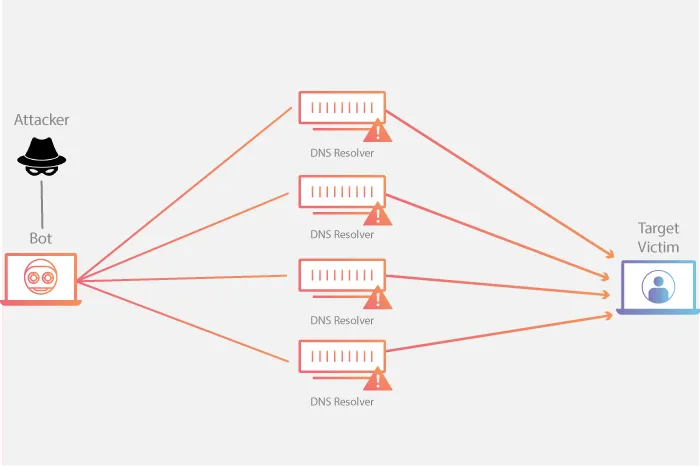
Looks pretty similar, no?
So, time for a little sidenote.
Technically even 10k requests + some organic traffic shouldn’t kill your site. Especially when it is deployed behind a CDN like Fastly or Cloudflare.
“It’s FOSS” even says they are behind Cloudflare, which (in my humble opinion) points to some configuration mistake? Their content is mostly static files, a CDN should catch that just fine.
I’m also not scared of this post going semi-viral. This blog is (as of the time of writing) hosted on Vercel. Their edge networks and CDN should catch this quite nicely (this blog is literally 100% statically generated HTML and CSS, no JavaScript at all).
So, you see how that can become an issue.
It also has been recognized by the Mastodon devs and they promised to look into it and hinted at a solution.
(Spoiler: That didn’t happen)
So, what can we do to attempt to fix this?
While the solution I’m gonna propose here won’t reduce the fetches across the Fediverse to a single fetch, I think (if done properly) it can alleviate most of the problems.
Okay, here it comes (and this will sound weird coming from someone who is all for decentralization): We centralize the fetching to some extent.
Hear me out here. Let’s lay out our components here. We have:
- The server hosting the content that the link points to. Let’s call it “article host”.
- The server that the link was posted to. Let’s call it “fediverse server”.
- The server that downloads the content from the article host, processes the metadata, and then provides it to the fediverse server. Let’s call it “embed server”.
The third part is our (partial) solution here!
But how does creating a separate server solve anything here? Well, see, we can make this server a communal resource. Multiple closely aligned servers use the same server.
Let’s say.. corteximplant.com, nightcity.bar, and hackers.town use the same embed server. This embed server caches the processed metadata for every link in-memory using an LRU cache (or maybe even persists it to disk, who knows).
That way, when all the instances receive the link, they hammer the embed server for the metadata. And the embed server, it can coalesce the requests or serve from cache.
So instead of making it three separate requests, it gets reduced to one.
Here’s another diagram, just for fun:
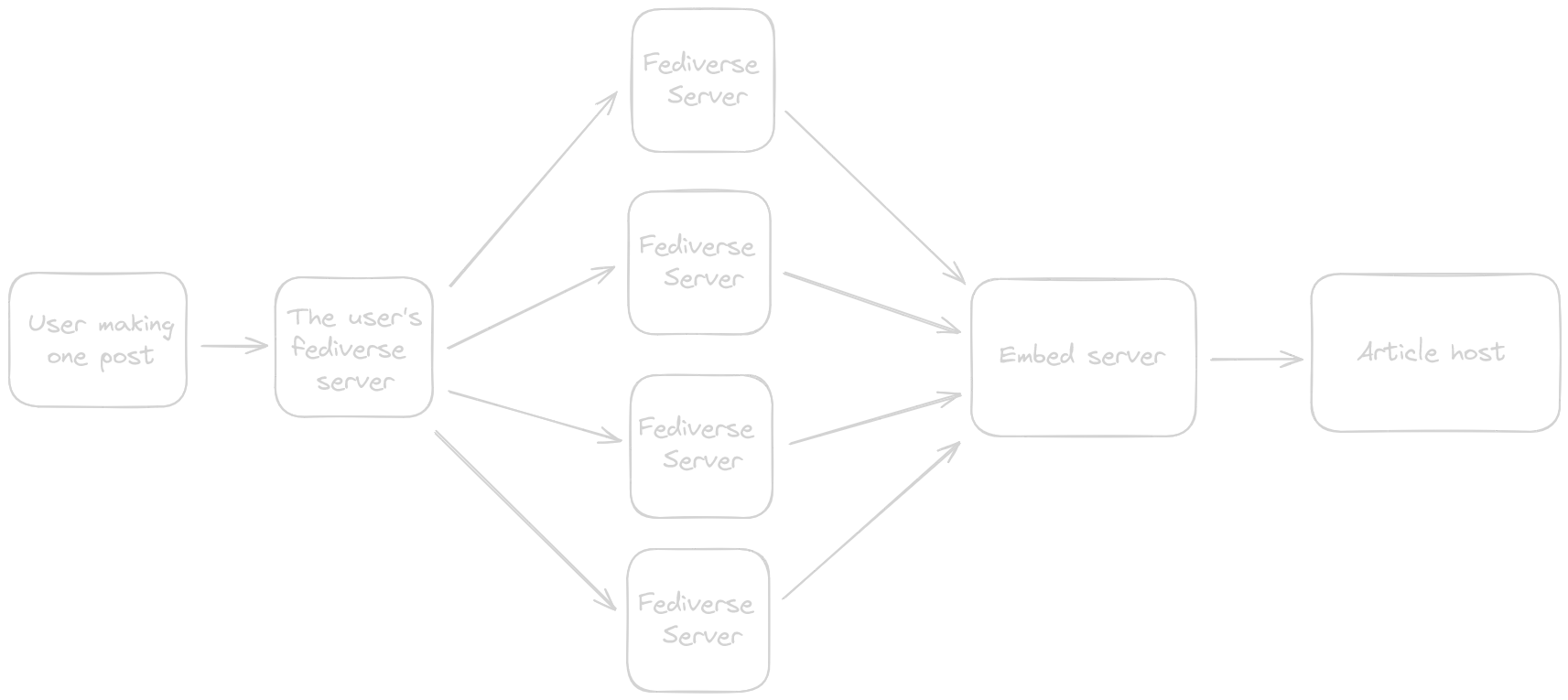
Now scale this up! Imagine 100-200 servers are using the same embed server. That reduces the requests by a factor of.. well $N$ where $N$ is the amount of fediverse servers connected to the same embed server.
That’s massive savings! Instead of $N$ requests, we make it 1.
But that requires cooperation in multiple places to work.
We need Fediverse server developers to create a embed server implementation (or API definition) and make the servers capable of fetching metadata through that embed server.
And we need instance admins to talk to each other, organize groups of moderate scale, and then connect to the same embed server.
That sounds like a pipedream
Well, not really! We have proof that communal projects on the Fediverse can work and the technical groundwork already.
So, first for the proof. There is this great project called Jortage which is a bunch of Fediverse servers cooperating (85 as of the time of writing) and saving storage that way.
They provide an Object Storage pooling solution. Instead of each instance having a separate S3 bucket, they all connect to a Jortage ingest server which checks if the file is already in the pool.
If it is, the file is not uploaded and they just return a reference to the already existing file. They all donate to keep this project running, and they saved 33.34TiB of storage space! And that number will just keep growing.
So if you are an instance admin and have a few spare bucks and want to save on storage, maybe migrating over to Jortage and supporting the project is something worthwhile for you
Now for the technical stuff..
Like I said in the beginning, we already have the technical groundwork for such an embed server, and I wasn’t kidding when I said that.
There is the excellent project called Lantern Chat by novacrazy, and they extracted their embed service into a separate project.
This service does what we are looking for: load a page, parse its metadata, and return it in a normalized form.
It is free software on GitHub, and already used by my Fediverse server, Kitsune.
Nova is an incredibly talented person, and he is actively looking for donations on either GitHub Sponsors or Patreon.
If you have a bit of money spare, please definitely consider donating a few bucks to him. I’m sure he will appreciate it!
Some links: His patreon and his GitHub Sponsors.
So it is definitely viable to use that as the embed server we hypothesized about earlier, put it behind an NGINX reverse proxy, and cache the responses by the body contents.
It doesn’t do the request coalescing yet, but that is something that can be implemented into the Lantern Chat embed server. Because that kind of bookkeeping is easier to implement than the mess that is handling all the possible embed metadata sources.
Conclusion
Well.. the conclusion is pretty simple: The current situation is like it is because of a naive implementation that just never changed. It wasn’t a big problem until the Fediverse started to grow.
It’s classic growing pains. No malice or incompetence. And we can, at least partially, solve this by cooperating.